
CS234 Winter 2019 1강 - Introduction
강좌 슬라이드 : http://web.stanford.edu/class/cs234/schedule.html
기록을 위한 것이지 보여지기 위한 것이 아닙니다.
RL 초보자이기 때문에 이해한 것이 정답과 다를 수 있습니다.



how can an intelligent agent learn to make a good sequence of decisions?
intelligent agent (not human or biological) make a whole sequence of decisions.
Fundamental challenge in arti cial intelligence and machine learning is learning to make good decisions under uncertainty
good이라는 것은 optimality의 개념과 유사하다.

Yael Niv : psychologist and neuroscience researcher over at Princeton
원시 생명체의 경우 유년기 뇌를 가졌지만 성인이 되어 뇌가 소화되어 사라짐
- 더이상의 결정 필요성이 없기에 뇌가 사라진 것
이것은 왜 agent가 intelligent어야만 하는가를 보여주는 생물학적 예
2015 DeepMind Nature이 Atari game들을 통한 RL의 획기적 결과물을 보임
비디오 게임은 복잡한 일들을 수행하는 매우 훌륭한 예
agent가 pixel 입력으로부터 학습을 시켰다는 것이 매우 획기적인 일
교수 자신이 RL을 시작할 때 많은 부분들이 toy problem에 집중되어 있었다. large scale application에 있어 어려움을 겪었지만 지난 5년동안 큰 발전을 이루었다.
California Berkeley ...
로봇이 집거나, 옷을 접는 것들을 할 수 있다.
Figure: RL used to optimize Refraction 1,
Madel, Liu, Brunskill, Popvic AAMAS 2014.
교육용 게임들에 있어 AI가 사람의 잠재력을 끌어낼 수 있는 방향으로도 발전하는데
목표는 빠르고 효율적으로 분수와 같은 것들을 가르칠 수 있게 만드는 것
Where the goal is to figure out, how to quickly and effectively teach people how to learn material such as fractions.


교수의 말에 따르면 불활실성으로부터 훌륭한 선택들을 하도록 학습시키는 것을 강화학습이라고 칭했지만 근본적으로 가지고 있는 4가지의 중요한 요소들로
Optimization, Deplayed Consequences, Exploration, Generalization을 이야기할 수 있다.


결정들은 후에 큰 영향들을 미친다.
지금의 결정이 후에 어떤 결과로 영향을 미칠지는 모른다.
예) 초콜릿을 먹고난 한 시간 후 먹어서는 안됬는데라는 사실을 깨닫거나
게임에서 key를 얻는 것이 결과적으로 도움이 되었다는 사실
이것들의 어려운 점은 즉각적으로 결과를 받지않기 때문에 중요한 문제를 풀 때 어떤 결정을 내려야할지이다.
이것은 다른 ML과는 다른 특징이다.

Agent는 경험을 토대로 학습을 시도하고 결국에는 성취한다라는 점이 과학자와 비슷하다.
여기서 어려운 것은 데이터가 검열된다는 점이다. 다시 이야기하면 결정에 대해 보상을 얻을 수 밖에 없기 때문에 다른 시도들에 대한 결과는 알 수 없다.
예) stanford에 온것은 그 당시 최적의 결정이었겠지만 인생의 시도는 한 번이기 때문에 MIT에 갔을 때의 경우 어땟을지는 아무도 모른다.

Atari 게임을 예로들면 여기서 pixel로부터 학습을 하는데 프로그램한다고 가정하면 엄청난 양의 프로그램을 해야하고 이것은 쉬운 일이 아니다
tractable 다루기 쉬운
때문에 우리는 일반화 Generalization을 해야한다.
이것을 통해 설령 우리가 보지못한 pixel 단위의 행동이 나와도 agent는 무엇을 해야할지 알고 있다.

다만 Optimization, Generalization, Delayed Consequences는 포함하지만 Exploration은 포함하지 않는다. 이유는 이미 결정을 내릴 때 많은 경우의 수를 두기 때문에 탐험이나 모험이 필요하지 않고 최적의 수를 둘 수 있다.
보상을 알고있다고 해도 env world에서의 어떤 결정이 영향을 미칠 수 있을지 계산하는 일이 어렵다.

Label이라는 Dataset 답을 가지고 학습하기 때문에 Exploration이 포함하지 않는다.
Delayed Consequences 역시 답이 이미 존재하기 때문에 항상 답이라는 사실을 알고있다.
때문에 지연되었던 아니던 결과는 항상 참이다.

비지도 학습이 분명한 답을 가진 것은 아니지만 classify가 가능하다는 점에서 partial credit을 준다.

Figure: Abbeel, Coates and Ng helicopter team, Stanford
Andrew Ng
매우 전도유망한 Imitation Learning & RL

game theoretic 역시도 마찬가지

Agent는 행동을 취하고 이를 통해 World의 상태가 영향을 받으며 관찰과 보상의 형태로 되돌아간다.
Expected라는 단어가 중요한데 우리가 기대하는 미래로의 보상을 최대화하는 agent를 시도하는 것이 목표이다.


다만 시간이 오래 걸릴 것 같다

-0.05 약물 부작용이 있을시의 보상을 준다.


어떻게 보상을 선택할 것인지에 따라 Tutoring에서도 많은 고민이 필요
우리는 agent 자체가 우리와 상호작용하는 것을 무시할 것이다
그럼에도 현실문제에서는 중요한 문제
sub-discipline of ML : 5~10년 정도된 흥미있는 분야
흥미로운 아이디어 중 하나 : 만약 2개의 agent가 상호작용한다면 서로 도울 것인가





state vs history
corridor 1. 복도, 회랑 2. (기차 안의) 통로
state는 History를 사용하여 결정을 내릴 때 사용하는 정보
local state는 현재의 state만을 가르킨다 = 현재의 observation
Markov Assumption : 많은 state 상태에서 history로 예측한 결과 = state 예측 결과

ex) 고혈압
현재의 혈압과 행동은 약을먹을지 말지의 상태를 나타냄 Markov?
다양한 상태로 일시적인 혈압상승의 경우도 있을 수 있으므로 not markov state
웹사이트 쇼핑
고객이 상품을 보고있는 상태에서 어떤 상품을 추천 Markov?

state = history => markov


Healthcare (don't see all physiological processes)


현재 나의 고객이 준 의견이 다음 단계에서 영향을 미친다

a sufficient perfect model of the world들은 사실 deterministic 처럼 보인다.

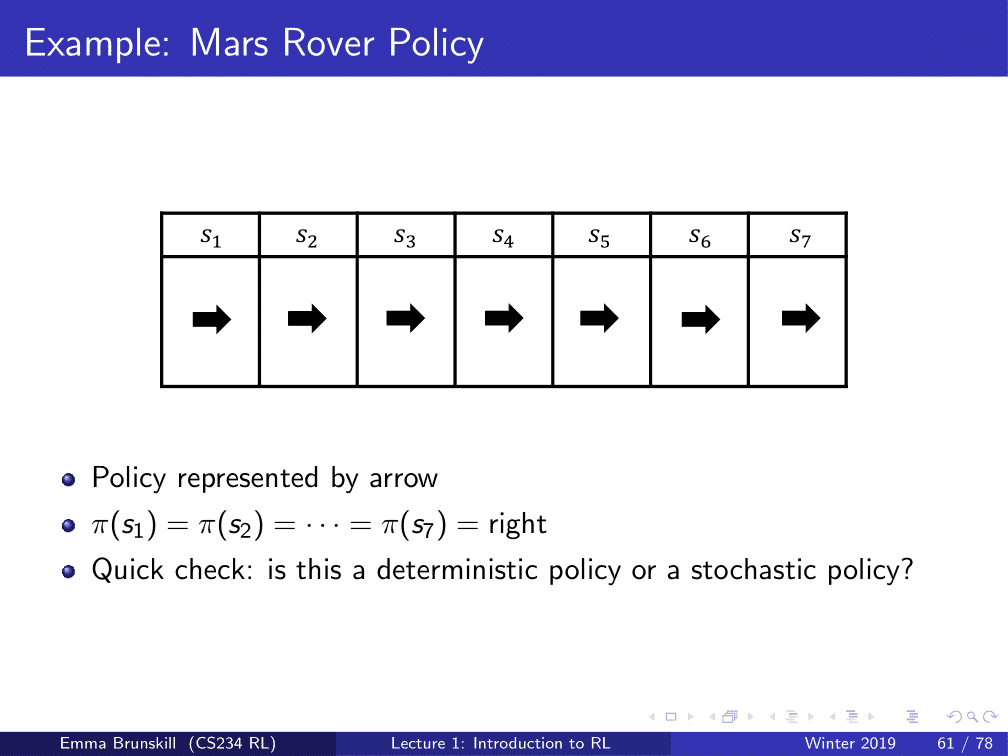
7개의 state가 있다.
좌우로만 움직일 수 있을 때의 Markov Decision Process를 볼 수 있다.


Transition / dynamics model은 다음 agent 상태를 예측한다.



0
gamma != 0 => 미래 보상에 영향을 끼치는 state를 고려한다


항상 정책을 계산, 이해하지만 분명한 상태에 대한 표현이 있을 수도 없을 수도
r(s)
r(s,a)
r(s,a,s`)
isomorphic 같은 모양의, 동일 구조의, 등정형(等晶形)의
가장 흔한 value function에 대한 내용은 r(s,a )이고 이것은 너가 어떤 state에 있을 때 내가 특정 행동을 고르고 보상을 받고 다음 state로 이행하겠다는 의미







tradeoff 거래, 교환
Exploration과 Exploitation 간의 선택의 기로에 서는데
Exploration은 미래에 좋은 결정을 할 것같은 것에 도전, 시도하는 것
Exploitation은 과거의 경험으로 좋은 보상을 얻을 것 같은 것을 선택하는 것이다.
좋은 보상을 놔두고 탐험을 선택을 하도록 정책을 수립할 것인지에 대한 딜레마

Exploration 새로운 도전
Exploitation 경험에 기댄 행동

새로운 정책을 만드는 것이 아님
Control : best policy를 최적화를 통해 찾는 것으로
일반적인 RL에서는 우리가 일일이 정책을 다 시도해볼 필요가 없고 다른 정책으로부터 평가를 통해 정책을 사용할 수 있게한다.




