
CS234 Winter 2019 5강 - Value-Function Approximation 공부
강의 슬라이드 : http://web.stanford.edu/class/cs234/schedule.html
기록을 위한 것이지 보여지기 위한 것이 아닙니다.
RL 초보자이기 때문에 이해한 것이 정답과 다를 수 있습니다.
더불어 한 번에 완성되는 글이 아니기에 글이 없을 수도 있음을 알려드립니다.
Copyright to Stanford CS & Emma brunskill
- Introduction
- VFA for Prediction
- Control using Value Function Approximation

(우리는 이제껏 유한한 state와 action이 존재한다고 가정)
실제 현실 세계에서는 거대한 state와 action space가 존재하기에 표의 형식이 충분하지 않다.
예를 들어 아타리 게임에서의 픽셀의 종류로써 state-space로 가정했지만 그것만으로도 충분히 거대한 공간을 차지했기에 table 형태로 단순히 적을 수 없었다.
cf) tabular 표로 나타낸
우리는 good decision 즉 훌륭한 결정을 하도록 설정하도록 학습할 수 있기에 과거의 경험을 가지고 Generalization 일반화를 할 수 있다.



representational capacity vs memory, computation, data


Decision Tree와 같은 방식의 강화학습 정책을 사용하면 사람들에게 직접적으로 상호작용할 것이다.
Deep Learning은 가령 의사에게 적용하면 환자에 대한 특정 치료법을 정당화하기에 비효율적일 수 있는 반면 highly interpretable하기 때문에 Decision Tree는 효율적일 수 있다.
우리 수업에서 2가지 이유로 Linear value function을 먼저 다룰 것
1. 작년까지 강화학습에서 잘 정립된 function approximator이기 때문
2. DNN에서의 계산적 사고를 생각하는데 도움이 되기 때문






장애물로부터의 각도와, 거리를 말할 때의 feature representation 예를 그림으로 그린 것
laser range finder로 전방 180도에서 물체가 있는지 없는지 파악
cf) elaborate 1. 정교한; 정성을 들인 2. (더) 자세히 말하다, 상술하다
why this is not markov?
floor 1,2 둘 중 어느 층인지 파악하기 어려움 -> 즉각적으로 센서로 읽어들이는 것은 동일하므로
aliasing 1. 컴퓨터 그래픽에서 해상도의 한계로 선 등이 우둘투둘하게 되는 현상

-> 하나의 상태에 대한 evaluating update를 진행, 이것을 each state들에 대해 진행해나감


episodic RL에서 Gamma=1으로 설정하지만
여기서는 일반적으로 필요하지 않다
episodes are always bounded
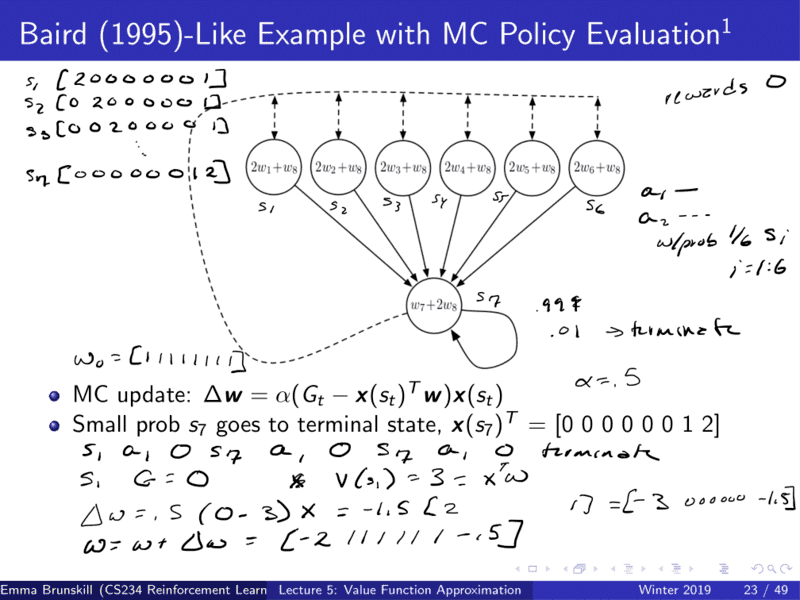
tabular representation과 비슷해보이지만 실제로는 더 많은 state들이 존재
7 states, 8 features ?
실제로는 feature representation은 true state 보다 더 많다.
reward 0 : 문제점
s1 시작
s1 a1 0 s7 a1 0 s7 a1 0 terminate : episode
MC update
w = [ 11111111]
s1 representation [2000013]
Q : SGD per state or episode?
-> per state


pathology 1. 병리학 2. (사람의 행동에서) 병적 측면




1. function approximation
2. bootstrapping
3. sampling
그러나 policy 정책은 유지 : 정책으로부터 데이터를 얻어 value를 추정하는데 사용
지도학습과(i.i.d condition)도 비슷한 면이 있다.
정책이 계속 변하는 non-stationary aspect의 종류가 아닌 단일 정책을 사용해서 가까운 면이 있다.




[s1, a1, 0, s7]
delta w = alpha(0 + 0.9 * 3 - 3) = alpha * -0.3


functional capacity is sufficient to represent the value
수용량이 value 표현에 충분하기 때문에 error가 0
무한한 데이터에 대해 tabular representation을 사용해서 모든 single state를 표현하고자 한다면 0이 된다.
결과적으로 TE의 error 값 포함 MC의 error의 값
MSE는 정책하에 state들의 분포를 이야기한다.
MSE has taken over distribution of the states under the policy







POV Projection Operator Value Function

받게 되는 데이터의 분포가 실제와 많이 달라지기 때문








